

When to Hire ML Engineers vs Data Scientists
Quick answer: The right hire depends on where your organization is in the ML lifecycle. Data scientists explore data, build models, and surface insights. ML engineers take those models and make them work in production. Most teams need both, but getting the sequence wrong costs months.
The confusion around ML engineers vs data scientists shows up in impactful ways: missed timelines, stalled projects, wasted budget, and confusion about who to hire next. Job descriptions blur the lines, so candidates will often position themselves across both roles. Hiring managers end up guessing which skill set will actually move work forward.
If you hire a data scientist when you need production, infrastructure and progress slow. Or, if you bring in an ML engineer before you’ve validated a use case, you end up building systems around unclear problems. Both paths drain momentum.
This guide gives you a clear way to decide based on what your team needs to accomplish next.
What Sets ML Engineers and Data Scientists Apart
Skip the definitions, and look at what each role produces during a normal week:
- A data scientist explores datasets and builds models to test ideas. Their output usually takes the form of insights, recommendations, or prototype models.
- An ML engineer takes those models and builds the systems that run them in production. They focus on pipelines and long-term performance. Their output shows up as working infrastructure.
Both roles use Python and work with models. But it’s that shared ground that creates confusion during IT hiring.
Here’s how they differ in practice:
The overlap sits in model development. Once a model needs to run in production, ownership changes.
Where Each Role Fits in the Machine Learning Lifecycle
Machine learning work moves through a sequence of stages. Each role takes responsibility at different points.
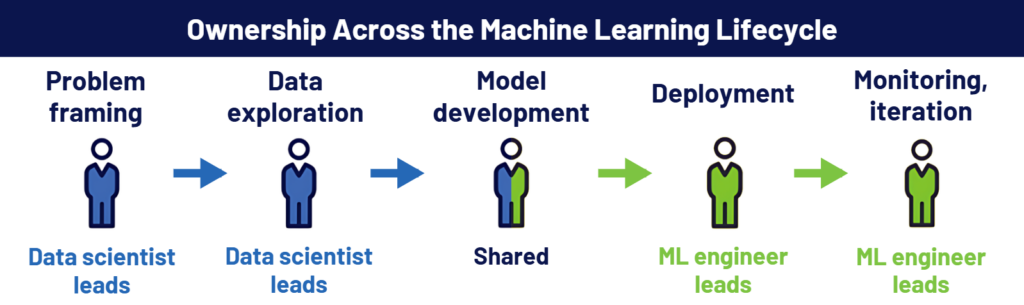
Breakdowns usually happen at the transition between modeling and deployment.
Some teams bring in an ML engineer before they have anything ready to deploy. Others expect the data scientist role to manage production systems. Both situations slow progress and create frustration.
Signs Your Team Needs a Data Scientist First
Early-stage teams usually struggle with direction more than infrastructure. Most teams haven’t narrowed in on a clear use case, so effort gets spread across too many ideas without real traction.
If you’re on the fence about hiring data scientists first, watch for these signals:
- You have data, but no clear questions. Data exists, but no one has defined what problems to solve or how success should look.
- Decisions rely on instinct. There’s no consistent analytical baseline guiding choices.
- No one has validated the opportunity. The team believes ML could help, but no one has tested whether the data supports the idea.
- Your models sit in notebooks. Early experiments exist, but no one has evaluated whether they should move forward.

Across industries, teams run into the same issue: weak problem framing or unreliable data leads to failed ML efforts.
Once a data scientist validates a use case, the direction sharpens. The team can focus effort where it will produce results instead of guessing.
Signs Your Team Needs an ML Engineer First
When models already exist, the challenge leans toward making them usable and reliable.
Look for these signals that you should hire an ML engineer first:
- Your model works in a notebook but stops there. The concept holds up, but there’s no production path.
- Data scientists handle infrastructure tasks. They spend time on pipelines or deployment instead of modeling.
- You run models manually. Someone has to trigger scripts rather than letting predictions run automatically.
- You need auditability and monitoring. Stakeholders expect version control, performance tracking, and visibility into model behavior.
A large share of ML models (frequently estimated in the 85-90% range) don’t make it into production, largely due to the complexity of deployment and infrastructure.
Hire machine learning engineers, and the system starts to stabilize. Models run on their own, and pipelines scale. Performance stays visible over time. That’s when ML becomes part of daily operations.
How to Sequence the Hires When You Can’t Do Both at Once
Most teams work with limited headcount, so sequencing matters.
Start with a data scientist in most cases. The exception shows up when you already have validated models waiting for deployment.
A single hire can sometimes bridge both roles for a short period. But that setup breaks down as soon as production needs increase.
Here’s a simple framework:
Teams run into trouble when they hire both roles without defining ownership. That creates overlap, slows decisions, and causes friction.
Strong sequencing keeps your machine learning hiring strategy aligned with how the work actually progresses.
How GDH Helped a Software Company Build the Right Team
A software company needed to strengthen its technical capabilities and move away from outsourced support. The challenge centered on identifying the right roles and building a team that could operate in-house.
GDH worked with them to define role requirements, align responsibilities, and build a hiring plan around those needs. They used a mix of contract-to-hire and project-based staffing to fill key positions.
The company moved to a fully in-house model with improved performance and a clearer structure. Read the full story about our approach.
This same challenge shows up in ML hiring decisions. Teams need clarity on what role fits their current needs. Once that’s in place, building the full capability becomes much more straightforward.
Still have questions about whether you need an ML engineer or data scientist? See our FAQ below.
Make the Right Hire at the Right Time
Hiring for ML capability rarely comes down to choosing the “better” role. It comes down to choosing the role that matches where your team is right now.
If your team is still figuring out what problems to solve and whether your data can support them, a data scientist gives you direction. If you already have models that need to run reliably and scale, an ML engineer turns that work into something the business can actually use.
Most teams will need both. The difference is timing.
When you line up the hire with the stage of your ML lifecycle, progress feels steady instead of stalled. You avoid rework, reduce friction between roles, and build toward a system that holds up over time.
Ready to hire an ML engineer or data scientist? Contact GDH to find pre-vetted specialists who fit your team’s current stage.
Frequently Asked Questions
Can a data scientist do the work of an ML engineer?
Some data scientists can handle basic deployment tasks, especially in smaller organizations. However, ML engineers specialize in production systems, automation, monitoring, and scalability, making them better suited for operationalizing machine learning models.
Do startups need an ML engineer or a data scientist first?
Most startups benefit from hiring a data scientist first because they need to validate use cases, understand data quality, and prove business value before investing heavily in production machine learning infrastructure.
What skills overlap between ML engineers and data scientists?
Both roles commonly use Python, machine learning frameworks, data processing tools, and statistical concepts. The difference is that data scientists focus on analysis and modeling, while ML engineers focus on deployment and system reliability.
Is an ML engineer a type of software engineer?
Yes. ML engineers are generally considered software engineers who specialize in deploying, scaling, and maintaining machine learning systems. Their work often includes cloud platforms, APIs, automation, monitoring, and production infrastructure.
Can one person fill both ML engineer and data scientist roles?
A single professional may cover both functions in early-stage organizations. As machine learning initiatives grow, most teams separate responsibilities to avoid bottlenecks and ensure both model quality and production performance.
Which role is more focused on business insights?
Data scientists typically spend more time translating data into recommendations, forecasts, and decision support. Their work helps organizations identify opportunities, measure outcomes, and prioritize initiatives before building production systems.
Which role is more involved with MLOps?
ML engineers are usually more involved with MLOps because they manage deployment pipelines, model monitoring, retraining workflows, version control, and infrastructure that keeps machine learning systems running reliably.
How do salary expectations differ between ML engineers and data scientists?
Compensation varies by market and experience, but ML engineers often command higher salaries when organizations require expertise in cloud infrastructure, distributed systems, deployment automation, and large-scale production environments.
When should a company hire both an ML engineer and a data scientist?
Organizations should consider both roles when they have validated machine learning use cases, active model development, and production deployment requirements. This combination supports the full machine learning lifecycle without overloading one team member.
What industries hire both ML engineers and data scientists?
Financial services, healthcare, retail, manufacturing, telecommunications, and technology companies frequently hire both roles to support analytics, predictive modeling, automation, personalization, fraud detection, and operational efficiency initiatives.
How does data engineering differ from ML engineering?
Data engineers build and maintain data pipelines, storage systems, and infrastructure for collecting and preparing data. ML engineers focus on deploying, monitoring, and scaling machine learning models once development is complete.
What is the biggest reason ML projects fail to reach production?
Many machine learning projects stall because organizations underestimate deployment complexity. Challenges such as infrastructure requirements, monitoring, governance, integration, and ongoing maintenance often prevent successful production implementation.





